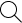

A giant screen in Jon Rafman’s 2025 Main Stream Media Network plays short, TV-like programs, comprised of mini “shows:” “Real Time Music,” a play on MTV; “Short Story 1,” a BBC-like interview program; and “Catastrophonics I-IV,” a series of uncanny “man-on-the-street”-type vignettes. They appear like regular programs, until we see otherwise impossible images – a winged deer flying and smoking a cigarette; bizarre bodily appendages; a person morphing into a trash bag – clear hallmarks of AI. Deriving their source clips from video models like Sora, Luma, Heygen, Runway, and Kling, Rafman’s videos emphasize byproducts of failure or “breakdown” that reveal the technology’s essence.
This dizzying effect, where objects impossibly transform, is an emergent signature of diffusion models, the technology powering many AI image generators. Such models operate through a process called “denoising:” First, in training, the model “sees” images mixed with varying levels of added noise (think: TV static). To generate images, the model reverses this process, starting with pure noise and progressively predicting versions with slightly less, eventually resulting in an image. Over time, as the model compares its predictions to the actual, less noisy images, it becomes a very accurate denoiser. Compared with previous image-generation architectures, such as generative adversarial networks (GANs), diffusion models have more diverse outputs, which make them easier to steer. Of course, they also have their shortcomings. For example, because denoising techniques often over-emphasizes pixel-level appearance over time or semantic coherence, video models often produce results that are physically impossible, defying gravity or object permanence.
Figure from Jonathan Ho, Ajay Jain, and Pieter Abbeel, “Denoising Diffusion Probabilistic Models,” 2020. See: arXiv:2006.11239 [cs.LG]
Despite the considerable effort demanded not only of their makers, but also of their viewers or interpreters, critics have often been dismissive, even contemptuous, of artworks made with AI. Take two prominent examples: In Spike’s Fall 2023 issue, “Field Guide to AI,” Mike Pepi writes: “the AI bros desire to remove the artist is an initial, if confused, attempt at a new aesthetics. The fetishization of computational supremacy gloriously combines with the utopian prospect of cleansing us of the interpretative baggage of history.” Ted Chiang, in a 2024 New Yorker entry called “Why A.I. Isn’t Going to Make Art,” writes similarly: “An artist – whether working digitally or with paint – implicitly makes far more decisions during the process of making a painting than would fit into a text prompt of a few hundred words.”
Both arguments are careless and unsound. First, they reduce the (yet unknown) possibilities for art made with AI to low-effort, quotidian generations, images generated from simple text prompts in widely available tools. But mass slop has nothing to do with art, just like photos to remember your parking space don’t implicate photographers, nor does a receipt degrade writing (and certainly has nothing to do with Proust). Next, they embody a conservative tendency in the history of art and technology to imagine sophisticated tools as compromising authorship. In photography, film, and computer-generated art, art canons only accepted works from the frontier of technology once the mediums’ gestures were well-defined. Most damning, however, is Pepi and Chiang’s dismissive incuriosity about the possibilities of these AI models, ignoring not only those working in traditional art contexts, like Rafman, but a larger community of researchers, engineers, and others whose works are establishing the grammar of a new visual language.

View of Jon Rafman, “Proof of Concept,” Sprüth Magers, Los Angeles, 2025

Jon Rafman, Short Story 1, 2025, eight-channel SD video, sound, 93 min. Courtesy: the artist and Sprüth Magers. Photo: Robert Wedemeyer
Photography’s earliest opponents attacked the technology on similar grounds: that the sophistication of the camera, relative to the paintbrush, degraded the potential for authorship. Such arguments, much like those of AI critics, attempt to remove an artist from the creation of a work. Describing these arguments in his 1987 essay “Action and Accident,” literary critic Walter Benn Michaels quotes an 1897 critic: “Whatever the photographer does when he presses a button, he does not make a picture … he starts a machine and the machine makes the picture for him.” In Benn Michaels words, “the intervention of the machine makes it look as though the photographer either has not done anything (the machine does the work) or has not done what he meant it to do (the picture is only an accident).” Contemporary readers would, of course, balk at this argument; we’d cite composition, framing, subject, and countless other controllable inputs. While early cameras were perhaps less controllable or convenient, new dials emerged to modulate shutter speed, aperture, and light sensitivity, and the photo-making began to require a technical skill wholly unrelated to painting.
Early computer graphics experiments, too, were met with harsh initial reception, as LACMA’s 2023 exhibition “Coded: Art Enters the Computer Age, 1952-1982” attests. Works like Ken Knowlton and Lillian Schwartz’s 1970 video Pixillation, which contrasts the natural and the computational by juxtaposing computer-generated animation, sixteen-millimeter handmade animation, and microphotography of crystal formations, failed to fit neatly into fine art, media, or computing contexts. These practitioners, likewise, refused neat categorization. Describing early collaborative works by Knowlton and Michael Harmon in her 2023 book, Peripheral Vision, media historian Zabet Patterson writes that “a coin was flipped to see who would be the engineer and who would be the artist – just one instance of how irrelevant these labels could be.”
Mass slop has nothing to do with art, just like photos to remember your parking space don’t implicate photographers, nor does a receipt degrade writing (and certainly has nothing to do with Proust).
The works that eventually entered art-historical contexts were those, like Pixillation, that focused most strongly on their apparatus. As Patterson writes, “[Schwartz] seemed inherently to feel that Knowlton had not pushed the limits of the instruments he was using – and that the best way to push those limits was to drill down into the particularities of the equipment.” Patterson suggests that studying the affordances of these technologies is essential to interpreting or appreciating them. These works entered institutional canons because they engaged with the jagged frontier of technology; why shouldn’t other significant works emerge from similar conditions?
Rafman is represented by a traditional commercial gallery and exhibits in art contexts. Much experimentation in AI, however, comes from practitioners without “art” backgrounds. Take Daryl Anselmo, an art director turned creative technologist. His works often show objects morphing into liquids, such as soap-like foam creatures emerging from the walls of a dimly lit bathroom, that epitomize the unlikely textures so characteristic of diffusion models. Further, counter critics like Pepi and Chiang, Anselmo’s work contends with endless creative choices. “[I’m trying to figure out] how I can recreate the idea I’ve got in my head. Which models would I use? Which techniques? How many steps, what aspect ratio, what would the prompt be? Do I need to train a LoRA [Low-Rank Adaptation, a technique for tuning the style of a model]?” A regular reader of Dreaming Tulpa, a newsletter that summarizes recent technical research papers, Anselmo has begun to experiment with new techniques himself. Some works are in the register of research, including his “Regions” whitepaper, which lays out a technique he discovered for applying multiple prompts to different parts of an image.


Examples of channel packing masks in Daryl Anselmo’s white paper “Regions,” 2024. Courtesy: Daryl Anselmo

Source images are converted into attention masked ipAdapters in Daryl Anselmo’s white paper “Regions,” 2024, featuring unsettling greek revival, with pink clouds and corpse flowers - June 23, 2024. Courtesy: Daryl Anselmo
Another creator of this flavor, Bennett Waisbren, began by observing generative art forums. “I would constantly be on the lookout for interesting workflows people were sharing on Discord or Civitai [a website for open source generative AI],” he told me. “I got started so early with the experimentation, before I knew what I was doing, I was just trying to see what I could break.” Waisbren learned to make custom workflows in ComfyUI, a generative media tool, by first reverse engineering community workflows, before creating original ones he now uses regularly.
Against the backdrop of this rich experimental culture, it’s increasingly ridiculous to imagine that AI models have no levers or customizability. Not only is there immense room for creative agency in existing levers (and their current use); controllability is perhaps the distinguishing feature of such tools. Jascha Sohl-Dickstein, widely credited as the inventor of the diffusion model, distinguishes diffusion models from previous image-generation architectures, like GANs, because of how easily one can constrain their output. “Diffusion models are more desirable because they’re very controllable,” he said over Zoom. “Because you are taking really small steps, you can slightly perturb the model at each one.”

Stills from Daryl Anselmo, irish spring, magically delicious, 2025, video, 36 sec. Courtesy: the artist

Technical details like these constantly provide new territory for experimentation; mechanical quirks become part of the image. For example, while public details aren’t available, ChatGPT’s image generator seems to abandon denoising in favor of an “autoregressive” architecture, which, like language models which generate text one token or word at a time, generates images by predicting small image patches, left-to-right and top-to-bottom. Different architectures tend to provide different knobs and have different visual signatures, the specifics of which many machine-learning researchers disagree about – and which are thus ripe for artistic experimentation.
There’s an interesting inversion between the technical and the cultural in how meaning is encoded. In his 1961 essay “The Photographic Message,” Roland Barthes writes that “a photograph is a message without a code.” Its meaning, rather, is determined by existing culture; a tomato in an advertisement is not a literal tomato, but connotes freshness, summer, or “Italianicity.” Barthes directly cites Claude Shannon’s information theory, a series of mathematical techniques for encoding and decoding information initially developed for telephones at AT&T’s Bell Labs. Techniques from the discipline are at the heart of diffusion models, used to evaluate the accuracy of image predictions (KL divergence) and to determine levels of noise (entropy).
In essence, there is a sort of slippage between production and perception, where the viewer begins to “read” techniques or architectures from the outputted image.
While Barthes describes culture in terms of technical encoding, we can understand AI images as culturally encoding their technological quirks. In other words, AI images are best interpreted and critiqued through understanding the technical mechanisms that produce them. As philosopher Vilém Flusser writes of new media in “Our Images” (1983), “apparatus transcode symptoms into symbols, and they do it in function of particular programs. The message of technical images must be deciphered, and such decoding is even more arduous than that of traditional images: the message is even more ‘masked.’” In essence, there is a sort of slippage between production and perception, where the viewer begins to “read” techniques or architectures from the outputted image. Visual cues become tells for use of a certain LoRA or image model; a sophisticated reader can see production techniques in a finished image.
Works could also engage with chance. Anselmo notes that he will sometimes make hundreds of versions of a video, using computational and manual techniques to narrow down a result. Rafman’s experience is similar; “a lot of the work is that of curation, because the image is infinitely created,” he said. This randomness might complicate our ability to describe artistic intention, but can also create new possibilities. Designer and critic Celine Nguyen writes: “When an artist uses chance procedures, they may not be the author of the output. But they become the author of the system that produces the output.”

Still from Bennett Waisbren, The one-hoof wonder, 2025, Instagram Reel, 7 sec.

Still from Bennett Waisbren, Feeding an old friend, 2025, Instagram Reel, 7 sec.

Still from Bennett Waisbren, Pig in the ball pit, 2025, Instagram Reel, 5 sec.
The most exciting path forward for AI-image-making is one self-liberated from the technologies that have preceded it. This is, of course, old-fashioned medium specificity. Take critic Clement Greenberg, writing “Modern Painting” in 1960: “Each art had to determine, through its own operations and works, the effects exclusive to itself. By doing so it would, to be sure, narrow its area of competence, but at the same time it would make its possession of that area all the more certain.” An art form that avoids becoming a cheap imitation of painting or photography, that emerges into something altogether new, will do so by leaning into what’s essential about AI.
As banal AI images come to supersaturate our visual culture, we should look with more curiosity toward image-makers who explore the specific quirks of different models. Their experiments may not squarely look like art (nor like engineering, nor research), but it is precisely in this interstitial space where tinkering is likely to find the essence of the apparatus – and thus to discern what these tools are doing to art and culture. These experimentations form an early working vocabulary for art made with AI. Rafman notes that “it is still possible to become the next DW Griffith or Sergei Eisenstein of AI” – the technology’s visual hallmarks and cliches are yet undefined. Critics became too dismissive too soon; there’s meaning, wonder, and beauty to be found amidst the slop.
___
Looking for an open-source AI community? Daryl Anselmo and Bennett Waisbren both recommend the Discord channel Banodoco.